| Yolov5总结文档(理论、代码、实验结果) | 您所在的位置:网站首页 › yolov5 源码 › Yolov5总结文档(理论、代码、实验结果) |
Yolov5总结文档(理论、代码、实验结果)
|
本篇文章是对Yolo-v5的一个总结,全文一共分为四个部分。第一个部分主要介绍Yolo-v5的结构以及相对于之前版本的一些改进;第二部分是对Yolo-v5代码主要部分的解读,包括如何更换backbone的细节;第三部分给出了两次实验的结果和在测试集上的表现;最后一部分是我对Yolo-v5的简要总结和思考。 一、Yolo-v5结构首先我用一张图来简单说明Yolo-v5的前向过程:  图1 Yolo-v5简要前向过程 图1 Yolo-v5简要前向过程Yolo-v5相较于Yolo-v4来说改动不是特别大,最主要的区别在于对于anchor的处理机制,这个机制我觉得也是让Yolo-v5收敛快的核心,另外Yolo-v5的loss与之前的Yolo系列也有些差别,接下来我从输入、Backbone、Neck、Loss四个部分来介绍Yolo-v5的结构。 1.输入首先对于数据增强,Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式,Yolov3则没有采用这种数据增强,Mosaic的具体细节不在这里过多阐述,不过这种方式的数据增强对于小目标的检测有比较大的提升。不同于Yolov4的是,Yolov5在选定锚框比时采用了自适应锚框计算,此前的Yolov3和Yolov4都是先采用聚类算法在数据集中预先训练,选好9个anchor的宽高,但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。在train.py中的参数说明中,“noautoanchor”参数便是用来控制该操作,设置为ture则启用自适应anchor机制,设置为false则采用给定的anchor。 2.Backbone(以Yolov5s为例)Backbone部分Yolov5与Yolov4并没有太大区别,主要的区别在于Yolov5在输入之后增加了一个Fcos,我对于Fcos的理解是它其实就和Yolov2中的PassThrough-Layer类似,为了方便我借鉴一张网上的图片来理解:  图2 Fcos的切片操作(图片借鉴于网络) 图2 Fcos的切片操作(图片借鉴于网络)在一个channel上进行上图的操作,最终的channel数是原featuremap的四倍。相比于Yolov4,还有一个不同的地方是Yolov5设计了两种CSP结构,分别用在了Backbone和neck部分,CSP结构涉及到了depth_multiple和width_multiple两个参数,这两个参数使得整个Backbone的设计能够更加灵活,具体细节会在代码部分进行说明。 3.NeckYolov5的neck部分用到了上面提到的CSP结构,我觉得目的就是为了能够更好地与前面网络提取的特征进行融合,其余地部分就与Yolov4没有区别,主要用FPN+PAN来进行下采样和上采样,给出三个不同尺度的featuremap,用来进行预测。 4.LossYolov5相较于之前的版本,最大的改动就在这个部分,而这个部分最大的改动就是对于正样本anchor区域的计算。在之前的Yolo系列中,对于每一个ground truth(后面简称为gt),都有一个唯一的anchor与其对应,而这个anchor选择的方式就是选与gt的IOU最大的那个anchor,不考虑一个gt对应多个anchor的情况。Yolov5采用的匹配规则是:计算bbox和当前层anchor的宽高比,若宽高比大于设定的阈值,则该anchor与bbox不匹配,丢弃该bbox,认为其为负样本。剩下的bbox,计算它落在哪个网格内并要寻找出相邻的两个网格,认为这三个网格都可能是来预测该bbox的,这就和之前的Yolo系列有很大不同,单从这里来看现在的正样本anchor数量比以前至少增加3倍之多。也正是因为如此,对于一个bbox,那么至少有3个anchor进行匹配。对于loss函数的计算,总体还是分为三部分:类别损失、置信度损失和定位损失,在类别损失和置信度损失上仍然采用BCEloss,这与Yolov3和Yolov4相同,但是对于定位损失,即w、h、x、y的loss,采用了GIoU-loss。整个loss函数的定义我整理为如下表达式:  二、修改Backbone 二、修改BackboneYolov5的源码中,是将yolov5s的结构封装在“yolov5s.yaml”中,但是他没有单独写neck,将neck分开在了backbone和head里面。 第一部分是三个参数,第一个是数据集中的类别数,因为使用的是VOC2007的数据,所以类别是20,第二个用来调整网络的深度,第三个用来调整网络的宽度,具体怎么调整的结合后面的backbone代码解释。 # parameters nc: 20 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple第二部分是backbone部分: backbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, C3, [1024, False]], # 9 ]这部分是backbone部分的具体网络结构,四个参数的意义分别是: 第一个参数:从哪一层获得输入,-1表示从上一层获得,-2表示从上两层获得; 第二个参数:表示有几个相同的模块,如果为9则表示有9个相同的模块; 第三个参数:模块的名称,这些模块写在common.py中; 第四个参数:这个参数就与第一部分的“width_multiple”参数有关了,上面把width_multiple设置为了0.5,那么第一个[64,3]就会被解析为[3,64*0.5=32,3],其中第一3为输入channel(因为输入),32为输出channel,第二个3为卷积核大小,第四个参数为步长,没有设置则默认为1。对于第二行的[128,3,2]也是同样的道理,它会被解析为[32,128*0.5=64,3,2],第一个为上一层的channel即32,第二个参数还是根据“width_multiple”参数计算.剩下部分均按照这一规律计算,head部分也相同。 “width_multiple”参数的作用已经介绍过了,那么“depth_multiple”又是什么作用呢?在yolo.py的247行有对它的定义,具体代码如下: n = max(round(n * gd), 1) if n > 1 else n # depth gain 暂且将这段代码当作公式(1),其中gd就是depth_multiple的值,n的值就是backbone中列表的第二个参数:  以gd=0.33为例,当n=1时计算得出公式(1)中的n=1,计算出的n就代表了该模块有几个残差结构,当n=9时可以算出公式(1)中的n=3,说明有3个残差结构。 yaml文件的内容会在yolo.py中进行调用,相当于可以灵活地修改网络的结构,只需要修改“width_multiple”和“depth_multiple”两个参数就可以。 如果要替换backbone的话其实就只用在common.py中将需要的banckbone所包含的结构写出来,然后重新建一个yaml配置文件就可以。因为要求采用的backbone为 MobileNetV3-Small,所以首先在common.py中增加如下代码: class h_sigmoid(nn.Module): def __init__(self, inplace=True): super(h_sigmoid, self).__init__() self.relu = nn.ReLU6(inplace=inplace) def forward(self, x): return self.relu(x + 3) / 6 class h_swish(nn.Module): def __init__(self, inplace=True): super(h_swish, self).__init__() self.sigmoid = h_sigmoid(inplace=inplace) def forward(self, x): y = self.sigmoid(x) return x * y class SELayer(nn.Module): def __init__(self, channel, reduction=4): super(SELayer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, channel // reduction), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel), h_sigmoid() ) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x) y = y.view(b, c) y = self.fc(y).view(b, c, 1, 1) return x * y class conv_bn_hswish(nn.Module): def __init__(self, c1, c2, stride): super(conv_bn_hswish, self).__init__() self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = h_swish() def forward(self, x): return self.act(self.bn(self.conv(x))) def fuseforward(self, x): return self.act(self.conv(x)) class MobileNetV3_InvertedResidual(nn.Module): def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs): super(MobileNetV3_InvertedResidual, self).__init__() assert stride in [1, 2] self.identity = stride == 1 and inp == oup if inp == hidden_dim: self.conv = nn.Sequential( # dw nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False), nn.BatchNorm2d(hidden_dim), h_swish() if use_hs else nn.ReLU(inplace=True), # Squeeze-and-Excite SELayer(hidden_dim) if use_se else nn.Sequential(), # pw-linear nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), ) else: self.conv = nn.Sequential( # pw nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False), nn.BatchNorm2d(hidden_dim), h_swish() if use_hs else nn.ReLU(inplace=True), # dw nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False), nn.BatchNorm2d(hidden_dim), # Squeeze-and-Excite SELayer(hidden_dim) if use_se else nn.Sequential(), h_swish() if use_hs else nn.ReLU(inplace=True), # pw-linear nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), ) def forward(self, x): y = self.conv(x) if self.identity: return x + y else: return y然后在同一文件夹下新建配置文件“yolov5-mobilenetv3small.yaml”,配置文件的内容如下: nc: 20 # number of classes depth_multiple: 0.33 width_multiple: 0.50 # anchors anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # custom backbone backbone: # MobileNetV3-small # [from, number, module, args] [[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2 [-1, 1, MobileNetV3_InvertedResidual, [16, 16, 3, 2, 1, 0]], # 1-p2/4 [-1, 1, MobileNetV3_InvertedResidual, [24, 72, 3, 2, 0, 0]], # 2-p3/8 [-1, 1, MobileNetV3_InvertedResidual, [24, 88, 3, 1, 0, 0]], # 3-p3/8 [-1, 1, MobileNetV3_InvertedResidual, [40, 96, 5, 2, 1, 1]], # 4-p4/16 [-1, 1, MobileNetV3_InvertedResidual, [40, 240, 5, 1, 1, 1]], # 5-p4/16 [-1, 1, MobileNetV3_InvertedResidual, [40, 240, 5, 1, 1, 1]], # 6-p4/16 [-1, 1, MobileNetV3_InvertedResidual, [48, 120, 5, 1, 1, 1]], # 7-p4/16 [-1, 1, MobileNetV3_InvertedResidual, [48, 144, 5, 1, 1, 1]], # 8-p4/16 [-1, 1, MobileNetV3_InvertedResidual, [96, 288, 5, 2, 1, 1]], # 9-p5/32 [-1, 1, MobileNetV3_InvertedResidual, [96, 576, 5, 1, 1, 1]], # 10-p5/32 [-1, 1, MobileNetV3_InvertedResidual, [96, 576, 5, 1, 1, 1]], # 11-p5/32 ] head: [[-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 8], 1, Concat, [1]], # cat backbone P4 [-1, 1, C3, [256, False]], # 15 [-1, 1, Conv, [128, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 3], 1, Concat, [1]], # cat backbone P3 [-1, 1, C3, [128, False]], # 19 (P3/8-small) [-1, 1, Conv, [128, 3, 2]], [[-1, 16], 1, Concat, [1]], # cat head P4 [-1, 1, C3, [256, False]], # 22 (P4/16-medium) [-1, 1, Conv, [256, 3, 2]], [[-1, 12], 1, Concat, [1]], # cat head P5 [-1, 1, C3, [512, False]], # 25 (P5/32-large) [[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]为了与之前实验对比,所以“width_multiple”和“depth_multiple”两个参数与之前保持一致。 三、实验结果本次实验的结果均在NVIDIA GeForce RTX 2080 super上完成,每次训练都采用单卡训练,超参数均为源代码默认参数,epoch设置为300,batch-size设置为16。因为voc2007数据集本身是没有对数据集进行划分的,所以我自己用脚本划分了一下数据集,最终训练集有8467张图像,验证集有600张图像,测试集有896张图像。 Backbone:yolov5s 训练过程中类别损失、置信度损失、边框位置损失的曲线变化图如下:  图3 从左至右依次为训练过程中的类别损失、置信度损失、边框损失的曲线图 图3 从左至右依次为训练过程中的类别损失、置信度损失、边框损失的曲线图下图为训练过程中各类别的precision,recall和PR曲线图:  图4 从左至右依次为各类别训练过程中的precision、recall、PR曲线图 图4 从左至右依次为各类别训练过程中的precision、recall、PR曲线图训练过程中总体的precision、recall、[email protected]、[email protected]:0.95的曲线图如下: 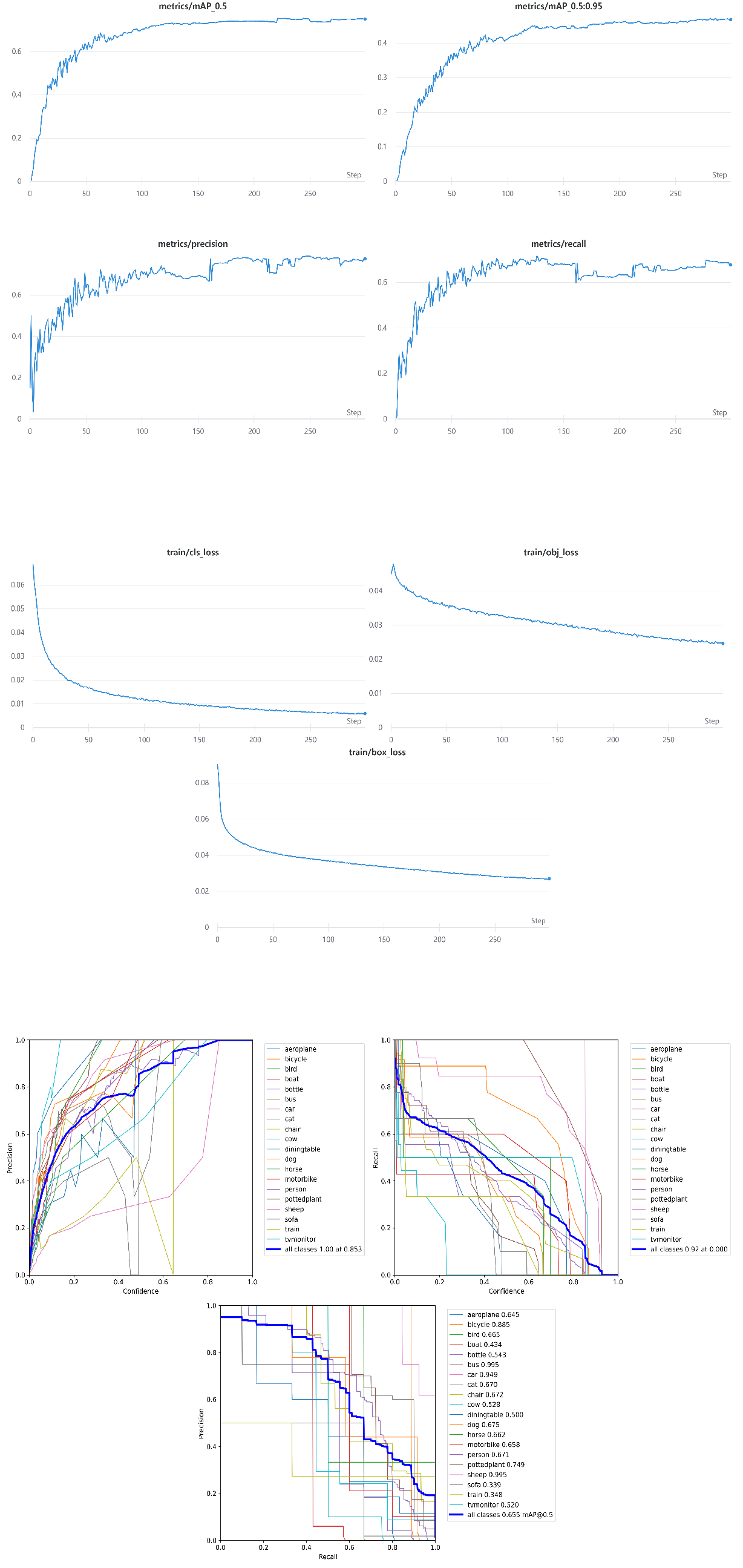 图5 训练中各项指标的总体曲线变化图 图5 训练中各项指标的总体曲线变化图训练完成后,该模型在测试集上的表现如下: 表1 Backbone使用Yolov5s在测试集上的结果 [email protected]@0.5:0.95all0.8220.6450.7520.475aeroplane0.8040.8250.9620.507bicycle0.9630.8750.9490.643bird0.8520.3750.5560.380boat0.9530.5000.5350.317bottle0.9300.5000.8400.511bus0.6760.7500.7690.568car0.7650.7100.8500.631cat10.5780.8270.586chair0.6750.6840.8030.470cow0.84810.9950.472diningtable0.7290.5000.7450.489dog0.8290.4170.5880.286horse0.8790.8110.8870.585motorbike0.98010.9950.771person0.9240.7370.8270.481pottedplant0.7720.4090.4980.192sheep0.8970.5440.8090.578sofa0.2840.3330.2090.155train0.9360.6000.7290.410tvmonitor0.7340.7500.6740.477Backbone:MobileNetV3-Small 训练过程中类别损失、置信度损失、边框位置损失的曲线变化图如下:  图6 从左至右依次为类别损失、置信度损失、边框损失的曲线图 图6 从左至右依次为类别损失、置信度损失、边框损失的曲线图下图为训练过程中各类别的precision,recall和PR曲线图: 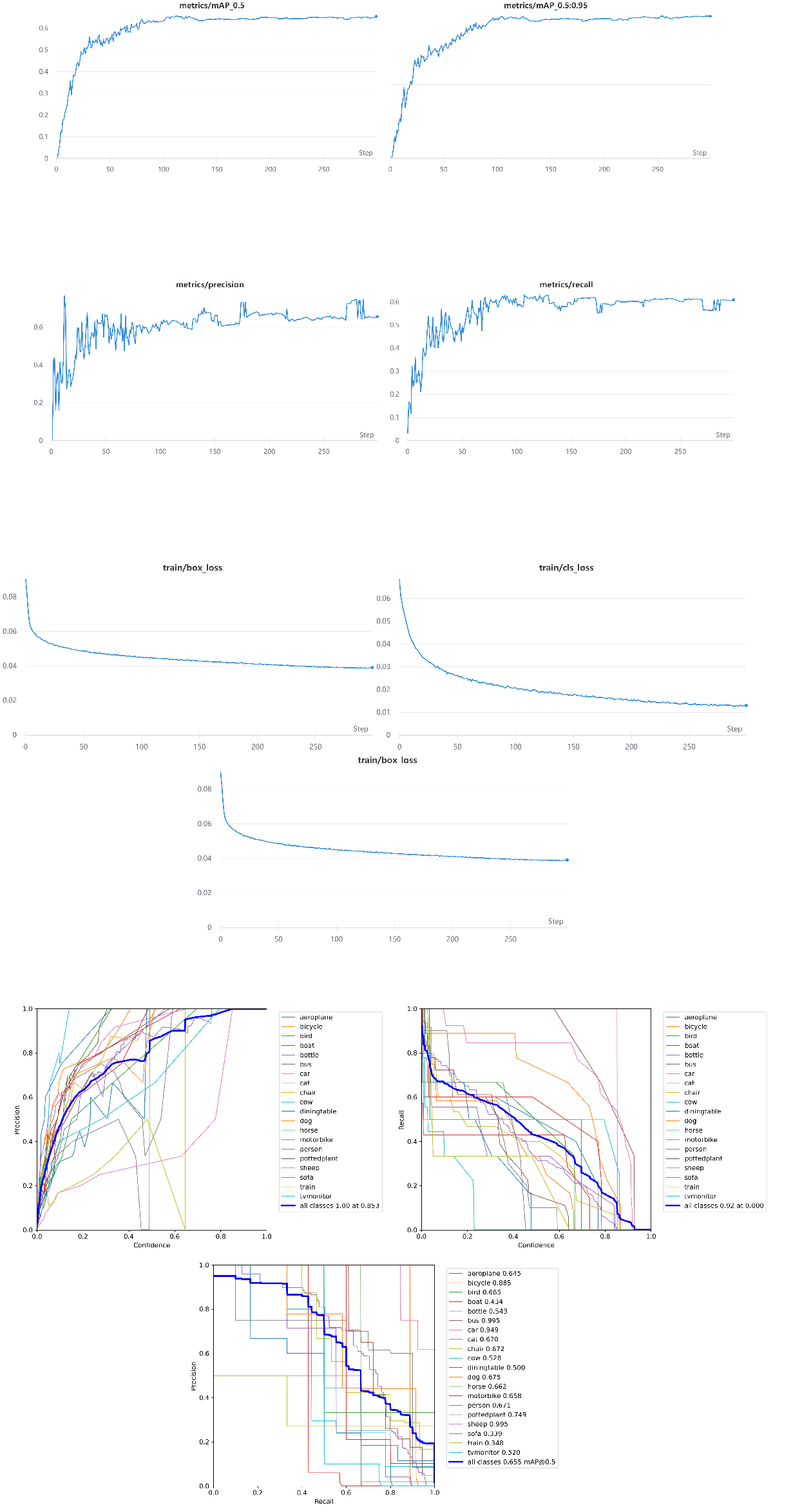 图7 从左至右依次为各类别训练过程中的precision、recall、PR曲线图 图7 从左至右依次为各类别训练过程中的precision、recall、PR曲线图训练过程中总体的precision、recall、[email protected]、[email protected]:0.95的曲线图如下:  图8 训练中各项指标的总体曲线变化图 图8 训练中各项指标的总体曲线变化图我截取了几张训练过程中的图,具体如下:   图9 训练过程中截取的图像,因为采用了Mosaic数据增强,所以每张图都是由几张图拼接而成的 图9 训练过程中截取的图像,因为采用了Mosaic数据增强,所以每张图都是由几张图拼接而成的在测试集上的表现如下: 表2 Backbone使用MobileNetV3-Small在测试集上的结果 [email protected]@0.5:0.95all0.6520.6070.6490.386aeroplane0.8830.6000.6400.430bicycle0.7750.8890.8850.500bird0.8330.6670.6650.283boat0.770.4290.4340.252bottle0.6920.5560.5430.332bus0.76710.9950.797car0.7600.8460.9490.726cat0.7180.6000.6700.295chair0.6810.4670.6720.305cow10.2180.530.275diningtable0.4550.5000.4840.155dog0.7300.5830.6710.412horse0.5690.5000.6620.463motorbike0.6390.6000.6580.336person0.6880.6330.6700.335pottedplant0.7170.5560.6430.373sheep0.21910.9950.697sofa0.4350.6670.3390.235train0.2360.3330.3480.109tvmonitor0.4690.5000.5200.418最后放上几张在测试集上的检测结果:   图 10 测试集上的检测结果 图 10 测试集上的检测结果这里再对两次实验做一个简单的总结:当Backbone使用MobileNetv3-small时,得益于其通道可分离卷积的设计,训练速度确实要快一些,在我的设备上使用yolov5s完成300个epoch的训练大概需要6个小时,而使用MobileNetv3-small只需要4.5小时左右,在网络参数上面MobileNetv3-small也占到了优势。但是从在测试集的表现来看,yolov5s在precision、recall、[email protected]、[email protected]:0.95四个指标上都超过了MobileNetv3-small,特别是在[email protected]这个指标上,高出了0.103。当然这只是两组实验,并没有进行太多调参等优化的工作,只能从宏观上大致认为两种Backbone的特点分别是快和准,具体使用哪个应该根据具体的使用场景来决定。 四、总结Yolov5从发布到现在已经过去一年,它的代码也是不断在进行更新,总的来说它在Yolov4的基础上又增加了一些tricks,让模型能够更快地收敛,最终的各项指标也都有一定程度的提升。我觉得最大的两个改动是:考虑了邻域的正样本anchor匹配策略,增加了正样本;通过配置参数,可以得到不同复杂度的模型。对于前者单从实验效果上来看确实有效,但我觉得这样直接增加正样本数量应该也会对网络训练产生一些负面的影响,缺少一些理论的可解释性,也有可能是我理解还不够。对于后者通过参数配置来改变模型的复杂度,确实使得在训练中能够更加灵活地调整结构去适应不同的数据集,我理解为手动增强模型的泛化能力,不知道这样说是否准确。 以上就是所有的内容了,里面有一些借鉴了其他大佬的理解,也有一些自己的理解和想法,如果有错误的地方,还请批评指正。 |
【本文地址】